Interview
Thomas Liebig:
KI-Systeme –
Vom Algorithmus
zum CO₂-Fußabdruck

Zur Person
Thomas Liebig ist Juniorprofessor an der TU Dortmund und konzentriert sich auf nachhaltige Anwendungen von KI im Bereich der Smart City. Er berät den IT-Dienstleister Materna beim Transfer Künstlicher Intelligenz in den öffentlichen Sektor und die Industrie. Er ist Dozent für Datenschutz und Ethik an der Universität Nikosia in Zypern/Griechenland. Zuvor war er Leiter des Bereichs „Data Analytics & AI“ von Materna. Er promovierte zur Prognose von Fußgängerbewegungen anhand von Bewegungsmustern an der Universität Bonn und dem Fraunhofer-Institut IAIS. Thomas Liebig war Teilprojektleiter im Sonderforschungsbereich 876 zu Maschinellem Lernen unter Ressourcenbeschränkungen.
Private Homepage, http://www.thomas-liebig.eu
Projekte:
- Sonderforschungsbereich 876 – Verfügbarkeit von Information durch Analyse unter Ressourcenbeschränkung: B4 Analyse und Kommunikation für die dynamische Verkehrsprognose, https://sfb876.tu-dortmund.de/SPP/sfb876-b4.html
- H2020 ICT 688380 VaVeL: Variety, Veracity, VaLue: Handling the Multiplicity of Urban Sensors, https://cordis.europa.eu/project/id/688380
- FP7 ICT 318225 INSIGHT: Intelligent Synthesis and Real-time Response using Massive Streaming of Heterogeneous Data, https://cordis.europa.eu/project/id/318225
Essential
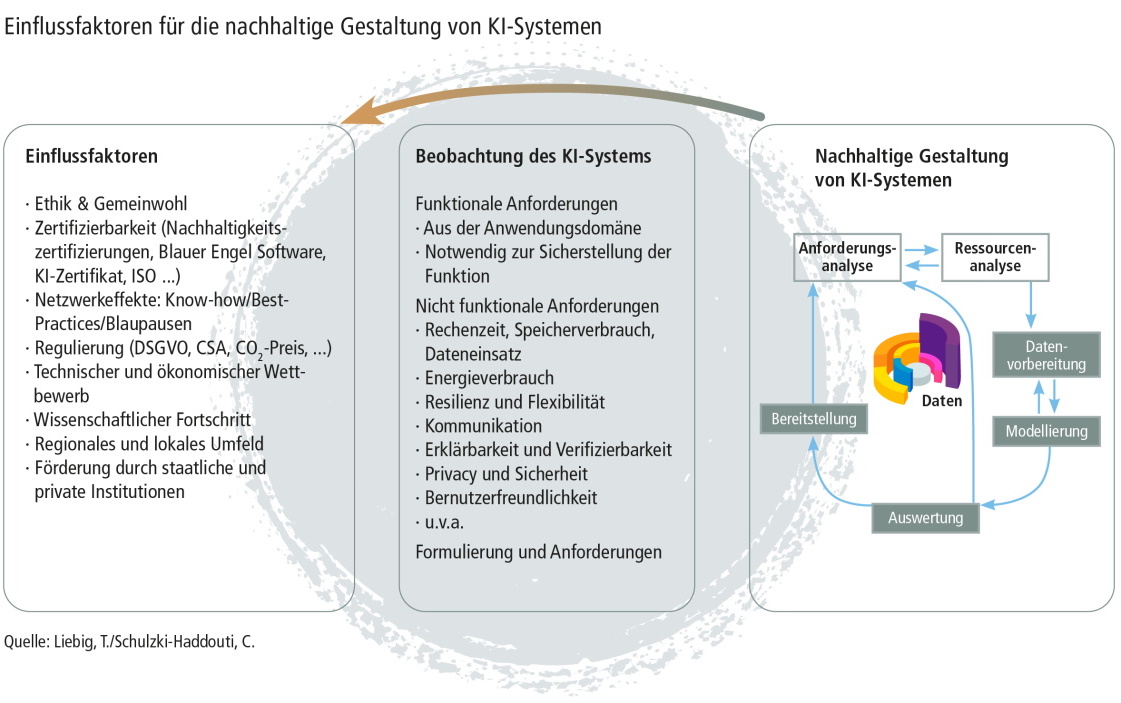
Thomas Liebig hält die Frage nach dem CO2-Fußabdruck von KI-Anwendungen wie etwa Apples Spracherkennung Siri für relevant. Insbesondere im Anwendungsumfeld könnten Unterschiede im Energieverbrauch einzelner Apps aufgrund einer hohen Zahl von Endgeräten eine große Rolle spielen. Allerdings ist darüber wenig bekannt wie auch über den Energieverbrauch des dahinterstehenden KI-Modells, das laufend nachtrainiert wird. Kosten-Nutzen-Analysen erfassen bisher nur den Bereich des Systembetreibers, nicht aber den des Anwenders.
Zertifizierungsansätze wie der „Blaue Engel“ erfassen zwar seit Anfang 2020 auch Software-Systeme, aber noch nicht Cloud-Anwendungen. Auch Resilienzkriterien werden noch nicht einbezogen. Gleichwohl spielen der Ressourcenverbrauch wie die Laufzeit und der Energiebedarf bei der Entwicklung neuer KI-Verfahren regelmäßig eine Rolle. Den CO2-Fußabdruck hält Liebig für ein relevantes Kriterium für die Bewertung des gesamten Systems etwa in der Planungsphase, doch in der Forschung spiele dieser bislang kaum eine Rolle.
Der Stromverbrauch spielt bei der Wahl eines KI-Modells eine Rolle, etwa wenn laufende Kommunikationskosten gesenkt werden sollen. Am Beispiel eines Routenplaners für die Stadt Dublin erläutert Liebig die Unterschiede zwischen einem zentralen und einem dezentralen Modell. So konnte mit einem dezentralen IoT-Modell mittels der „learning from label proportions“- Methode (LLP) der Kommunikationsaufwand um den Faktor 6 verringert werden. Das dezentrale Modell zeichnete sich überdies durch eine höhere Resilienz und Ausfallsicherheit sowie eine leichtere Erweiterbarkeit aus.
Ändern sich etwa im Rahmen der Verkehrswende die Ausgangsdaten für Routenplaner fundamental, wird sich auch das Modell weg von einem automobilzentrierten hin zu einem multimodalen Modell ändern. Ob und wie KI-Modelle nachtrainiert werden können und wie sich Modelle über eine längere Zeit effizient und handhabbar anwenden lassen, sind aktuelle Forschungsfragen. Dazu zählt auch die Frage, wie sich KIModelle unter Ressourcenbeschränkungen mit Blick auf Genauigkeit, Laufzeit und Anwendbarkeit effizient nutzen lassen. Ein Vorteil des von Liebig mitentwickelten dezentralen Modells besteht darin, dass erfasste Echtzeitdaten lokal aggregiert und anonymisiert werden, womit einzelne Bewegungsprofile nicht mehr erstellt werden können. Die Methode erlaubt so zuverlässige und datenschutzkonforme Aussagen zu Clustern, da auf dem Server mit KI-Methoden ausschließlich mit verschlüsselten Daten gerechnet wird. Allerdings benötigen diese Verfahren viel Rechenzeit und -leistung, weshalb sie noch nicht verbreitet angewandt werden. So gibt es bei der Anwendung kryptografischer Verfahren einen Trade-off zwischen Ressourcennutzung und Kosten.
Liebig erläutert, dass Datenmenge, Datenstrukturen, Datenspeicherung und Datenkommunikation die Effizienz eines Verfahrens und damit den CO2-Fußabdruck beeinflussen. Die Anwendung ressourcensparsamer Verfahren werde vor allem von regulatorischen Vorgaben zur Datensparsamkeit, den Energiekosten des Gesamtsystems sowie dem Einfordern bestimmter Systemeigenschaften in Ausschreibungen motiviert.

Empfohlener redaktioneller Inhalt
An dieser Stelle finden Sie einen externen Inhalt von YouTube, der den Artikel ergänzt. Sie können ihn sich mit einem Klick anzeigen lassen und wieder ausblenden.
Interview
KI-Systeme: Vom Algorithmus zum CO2-Fußabdruck
- Kennen Sie den CO2-Fußabdruck von „Hallo Siri“?
- Thomas Liebig: Nein, den kenne ich natürlich nicht. Siri ist eine verteilte Anwendung, die auf einer im iPhone verbauten App und einer Server-Anwendung beruht. Was genau im Detail dort abläuft, ist Firmengeheimnis. Aber die Frage, wie groß der CO2-Fußabdruck wäre, ist eine spannende Frage, da es bereits zwei Milliarden iPhone-Geräte gibt. Damit spielt es eine große Rolle, ob eine iPhone-App etwas mehr oder weniger Strom verbraucht.
- Die Hauptrechenleistung erfolgt ja auf der App, aber was ist mit dem Anlernen des Spracherkennungsmodells und seiner laufenden Pflege?
- Thomas Liebig: Auch dazu lässt sich wenig sagen. Sprachmodelle nutzen heute große neuronale Netze mit vielen Beispieldaten. Die großen Rechennetze, die dazu verwendet werden, bestehen größtenteils aus Grafikkarten, die sich für das Trainieren von neuronalen Netzen gut eignen. Sie verbrauchen für diese Aufgabe auch weniger Strom als die üblichen Haushalt-PCs brauchen würden.1
- Inwieweit lassen sich Kosten-Nutzen-Analysen für KI-Anwendungen anstellen, die eine Aussage zur deren Nachhaltigkeit treffen?
- Thomas Liebig: Ein KI-System wird häufig eingesetzt, um einen bestimmten Nutzen zu schaffen oder einen Prozess effizienter zu gestalten. Oder es gibt einen Prozess, der wie die Sprachverarbeitung neu geschaffen werden soll. In diesen Einführungs- und Umstellungsverfahren für diese Prozesse wird natürlich der Nutzen des Verfahrens bewertet und es wird abgeschätzt, welche Kosten damit verbunden sind. Kriterien wie Wirtschaftlichkeit, Effizienz und Nachhaltigkeit werden vor der Umsetzung abgewogen und im Rahmen von Machbarkeitsstudien bewertet. Beispielsweise bestand das Ziel im bereits angesprochenen europäischen INSIGHT-Projekt darin, den bisher manuell durchgeführten Prozess des Erkennens von Auffälligkeiten im Verkehrssystem mit Methoden der Künstlichen Intelligenz schneller und automatisiert auf Echtzeitdatenströmen durchführen zu können.
- Werden mit solchen Analysen nur die Kosten beim Hersteller oder Betreiber oder auch beim Anwender erfasst?
- Thomas Liebig: Es werden natürlich nur die Kosten desjenigen erfasst, der das System umsetzt.
- Werden bei einem Cloud-System also die beim Anwender anfallenden Kosten nicht erfasst?
- Thomas Liebig: Genau, das ist auch sehr schwierig. Um auf das Beispiel Siri zurückzukommen: Es gibt verschiedene Endgeräte, die die Spracherkennung nutzen. Das könnten weniger energieeffiziente ältere Geräte sein, aber auch modernere. Die Vielzahl verschiedener Endgeräte macht eine Betrachtung deutlich schwieriger.
Auf der Suche nach geeigneten Nachhaltigkeitskriterien
- Inwiefern gibt es Ansätze dazu, den CO2-Fußabdruck einer Anwendung wie Siri im Sinne des GHG-Protokolls komplett zu erfassen?
- Thomas Liebig: Man hat den „Blauen Engel“ Anfang 2020 für Software eingeführt und zertifiziert im Moment noch Desktop-Anwendungen, also Anwendungen, die lokal und nicht verteilt ablaufen. Hierfür wurden Test-Nutzungsszenarien definiert, ähnlich wie in der Verkehrssicherheit. So können bestimmte Vorgänge wie das Schreiben oder Formatieren eines Textes hinsichtlich ihrer Energiekosten und anderer Metriken bewertet werden. Das auf Cloud-Anwendungen zu übertragen, ist schwierig, doch das Konsortium hinter dem Blauen Engel um Professor Stefan Naumann von der Hochschule Trier will sich auch damit befassen.2
- Wird der Blaue Engel auch Resilienzkriterien abdecken?
- Thomas Liebig: Die Frage, ob die Systeme wartbar sind und ob sie erweitert werden können, ist angedacht. Aber gerade bei Cloud- Anwendungen halte ich eine Beurteilung für schwierig. Zudem dürfte das von der ökologischen Nachhaltigkeit eher abweichen.
- 1) Qasaimeh, M., Denolf, K., Lo, J., Vissers, K., Zambreno, J. & Jones, P. H. (2019): Comparing Energy Efficiency of CPU, GPU and FPGA Implementations for Vision Kernels; International Conference on Embedded Software and Systems, IEEE, S. 1 – 8.
- 2) Homepage des Umwelt-Campus Birkenfeld an der Hochschule Trier, Projekte im Bereich Green Software Engineering, https://www.umwelt-campus.de/forschung/projekte/green-software-engineering/home
- 1
- vorwärts
- Welche Rolle spielt die Idee der Suffizienz bei der Entwicklung von KI-Modellen?
- Thomas Liebig: Bei der Entwicklung neuer KI-Verfahren fokussiert man sich stets auf den Ressourcenverbrauch, also auf die Laufzeit, auf den Energiebedarf, etwa wenn es um eingebettete Systeme geht. Diese Metriken sind stets relevant. Beim Einsatz und bei der Auswahl eines bestimmten Verfahrens für eine konkrete Problemlösung, gilt es Verfahren zu verwenden, die entweder besser erklärbar und einfacher nachzuvollziehen sind oder die besser im Energieverbrauch sind. Das kann dann über Regulierung oder eine entsprechende Auftragsgestaltung gesteuert werden.
- Haben Sie schon einmal ausgerechnet, wie hoch der CO2-Fußabdruck einer von Ihnen programmierten KI-Anwendung ist?
- Thomas Liebig: Nein, das habe ich noch nicht gemacht. Wir berechnen üblicherweise einzelne Faktoren, die zum CO2-Fußabdruck beitragen. Der CO2-Fußabdruck eines KI-Systems wird dann interessant, wenn man beispielsweise in der Planungsphase das gesamte System bewerten möchte. Das spielt in der Forschung bisher nicht so die Rolle, da wir uns ja auf Einzelaspekte fokussieren.
- Aktuelle Studien3 haben versucht, den CO2-Fußabdruck und die Cloud-Computing-Kosten zu erfassen. Was halten Sie davon?
- Thomas Liebig: Ich halte das nicht für sinnvoll. Der CO2-Bedarf hängt neben den Algorithmen von vielen Faktoren der Implementierung und Hardware ab. Wegen der hohen Virtualisierung in heutigen Rechenzentren ist es schwer nachvollziehbar, welcher Teil eines Algorithmus auf welcher Hardware läuft. Was ist, wenn man morgen einen anderen Prozessor verwendet? Ich halte daher solche Gesamtbetrachtungen für realitätsfern. Teile eines Rechenzentrums werden ja regelmäßig durch effizientere Hardware ausgetauscht. Eine ganzheitliche Betrachtung des CO2-Wertes betoniert diesen dynamischen Prozess zu einer Momentaufnahme und gaukelt eine Gewissheit vor, die man so nie hat.
- Sollten wir mit Blick auf Klimaneutralität den CO2-Fußabdruck kennen oder würden Sie andere Messgrößen bevorzugen?
- Thomas Liebig: Wir sollten den CO2-Fußabdruck im Blick behalten, etwa bei der Ausschreibung von großen Rechenzentren oder KI-Systemen im öffentlichen Raum. Aber die einzelnen Größen, an denen man etwas ändern kann, sind andere. Hier achtet man etwa darauf, wie effizient eine Hardware für ein bestimmtes Problem arbeitet oder wie groß die benötigte Datenmenge für das Trainieren eines KI-Modells ist. Wir vergleichen Algorithmen und Verfahren danach, wie viele Ressourcen sie auf einem bestimmten Datensatz und einer bestimmten Hardware brauchen. Für den Vergleich wird vor allem der Energie- oder Speicherverbrauch einer KI-Anwendung oder ihre Laufzeit hinzugezogen.
- Welche Kriterien müsste der Ausschreiber erfassen?
- Thomas Liebig: Der konkrete Ausschreibungstext ist schwer zu formulieren mit Blick auf die stets erfolgende Steigerung der Rechenleistung und Energieeffizienz.4 Es ist nicht sinnvoll zu sagen, dass bestimmte Anwendungen mit bestimmten Eigenschaften einen bestimmten Energieverbrauch besitzen sollen. Stattdessen erscheint die Erfassung des Ressourcenverbrauchs einer Umsetzung immer nur im Vergleich zu anderen möglichen Umsetzungen sinnvoll. Dazu muss der Ausschreiber die infrage kommenden Umsetzungsformen kennen und einschränken.
- Was macht „nachhaltige KI“ also aus?
- Thomas Liebig: Die Frage der Nachhaltigkeit in der KI ist zu komplex, um diese kurz und knapp zu beantworten. Denn bei der Nachhaltigkeit von KI spielen viele Faktoren eine Rolle.
Die Gesamtbewertung des CO2-Ausstoßes ist nur für das gesamte IT-System durchführbar und sinnhaft. Bewertungen von einzelnen Aspekten wie Algorithmen, Hardware oder Implementierungen nach CO2-Verbrauch sind Momentaufnahmen und nur vergleichend sinnhaft. Die Aussagekraft solcher Gegenüberstellungen bleibt durch die kurze Halbwertszeit der Ergebnisse aufgrund des technologischen und wissenschaftlichen Fortschritts und der Vielzahl möglicher Implementierungen und regionaler Unterschiede begrenzt.
Die Fragestellung nach dem Ressourcenbedarf, die durch den Begriff „Grüne KI“ in den politischen Diskurs rückt, spielt seit jeher eine wesentliche Rolle in der Forschung zu Künstlicher Intelligenz und Maschinellem Lernen. An der TU Dortmund forschen wir dazu im Rahmen des Sonderforschungsbereichs 876 zur Datenanalyse unter Ressourcenbeschränkungen. Umso mehr ist es interessant, dass mit dem Transfer von Methoden der Künstlichen Intelligenz in Industrie und Gesellschaft dieser wissenschaftliche Diskurs auf Gesamt-IT-Systemebene unter dem Stichwort „Grüne KI“ fortgesetzt wird.
- 3) Schwartz, R., Dodge, J., Smith, N. A. & Etzioni, O. (2020): Green AI, in: Communications of the ACM, 63(12), S. 54 – 63; Strubell, E., Ganesh, A., McCallum, A. (2019): Energy and Policy Considerations for Deep Learning in NLP; https://arxiv.org/pdf/1906.02243.pdf
- 4) Koomey, J., Naffziger, S. (2015): Moore’s Law might be slowing down, but not energy efficiency, IEEE spectrum, 52(4), S. 35.
- zurück
- 2
- vorwärts
Zentralisiertes System versus IoT-basierte Netze
- Welche Rolle spielt der Stromverbrauch bei der Wahl eines KI-Modells?
- Thomas Liebig: Wir haben im Rahmen der europäischen Projekte INSIGHT und VaVeL für die Stadt Dublin bei der Routenführung mitgearbeitet und haben dort die Verkehrsmengen über die Zeit prognostiziert5: Wie viele Fahrzeuge tauchen wo in der Stadt an welchem Zeitpunkt auf, basierend auf den Schleifendaten, die in der Stadt verbaut sind? Wir haben sehr viele verschiedene Modelle entwickelt und getestet: zentrale und dezentrale Modelle.
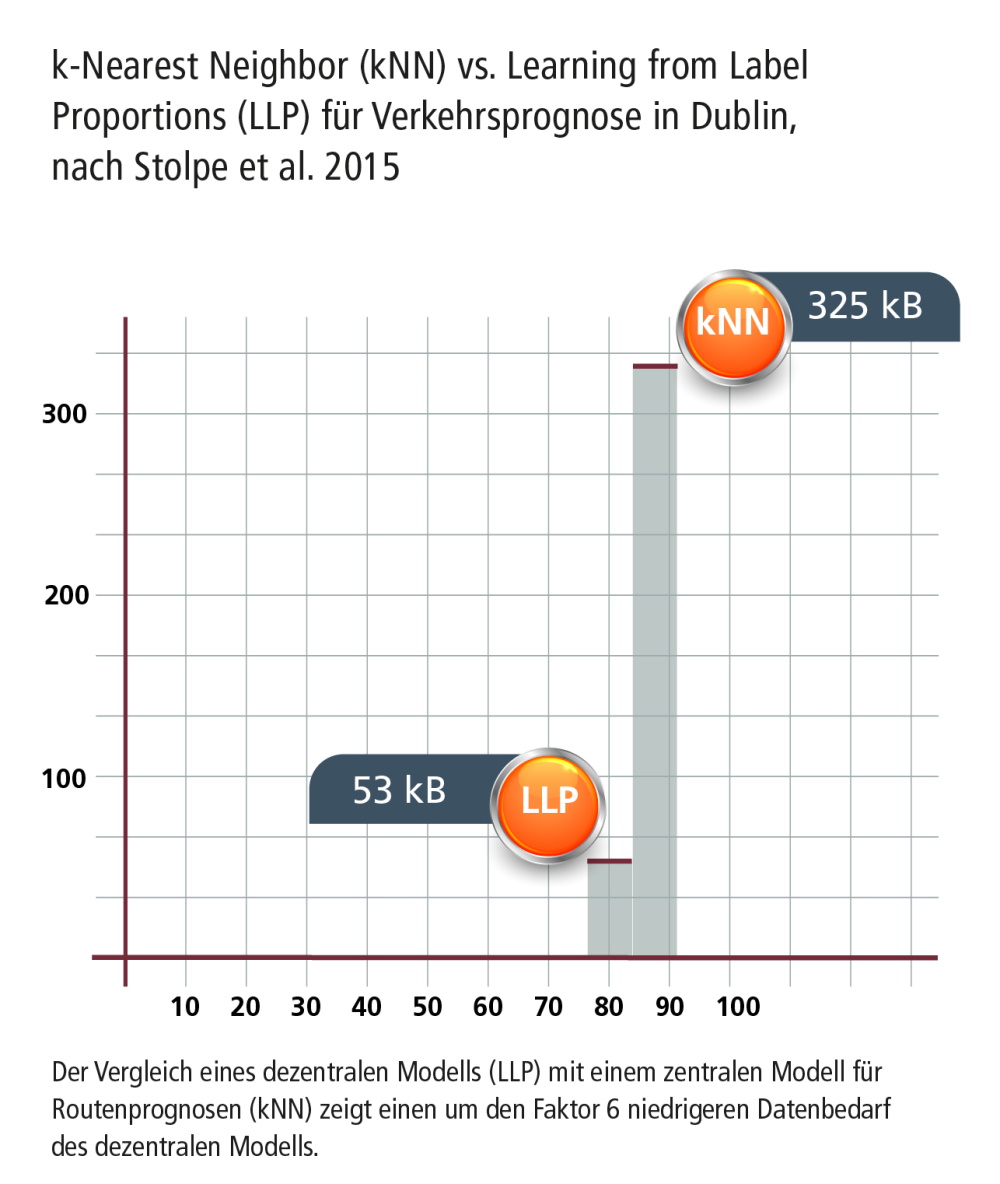
Bei den zentralen Modellen werden auf einem Rechner die Verkehrsprognosen erstellt, auf deren Basis die Routen bestimmt werden, mit denen sich Staus umfahren lassen. Dabei wurde auf die prognostizierte Verkehrsmenge optimiert, wobei die Fahrzeuge so verteilt werden, dass keine Staus entstehen.6 Wenn man aber jedem Verkehrsteilnehmer dieselbe Route empfehlen würde, würden Staus an Orten entstehen, die man vorher nicht auf dem Radar hatte. Deswegen ist es ein selbstorganisierendes Problem.7 Jeder Verkehrsteilnehmer braucht seine individuelle Route und eine Prognose für das, was geschieht, nachdem die Empfehlung an den Verkehrsteilnehmer ergangen ist. Das System berücksichtigt die Echtzeitdaten und schickt die Verkehrsteilnehmer dann dorthin, wo aktuell kein Stau ist, und auch dorthin, wo in Zukunft kein Stau sein wird, weil keine anderen Verkehrsteilnehmer hinfahren.
Dieses zentrale Modell haben wir mit dezentralen Modellen verglichen, bei denen wir geschaut haben, ob man das Verkehrsverhalten in der Zukunft prognostizieren kann, indem man die Daten von jeder Verkehrsschleife dort verwendet, wo sie entstehen, also lokal an den einzelnen Kreuzungen. Diese Daten haben wir lokal an den Kreuzungen gelassen und zur Prognose genutzt, wobei jede Kreuzung nur die Informationen der benachbarten Kreuzungen einbeziehen konnte.8
- Was konnten Sie bei Ihrem Vergleich der verschiedenen Modelle feststellen?
- Thomas Liebig: Mit dem dezentralen Modell hat sich der Kommunikationsaufwand um den Faktor 6 verringert. Wir erzielen im Vergleich zu einem zentralisierten Modell noch 93 Prozent der Genauigkeit bei gerade einmal 16 Prozent des Kommunikationsaufwands, da man nicht mehr zu jedem Zeitpunkt den Messwert kommunizieren muss. Wir aggregieren die Beobachtungen über die Zeit – das nennen wir „learning from label proportions“ (LLP)9 –, wobei wir uns über die Zeit die Verhältnisse der Beobachtungen anschauen und dann nur zu ausgewählten Zeitpunkten diese Verhältnisse kommunizieren. Wenn wir nur diese wenigen Verhältnisse zur Prognose nutzen anstelle jedes gelesenen Sensordatums, dann erhalten wir immer noch ähnliche Qualitätsmerkmale in der gewünschten Prognosegenauigkeit, aber mit deutlich weniger Kommunikationskosten. Das Ganze findet verteilt statt, womit wir eine höhere Resilienz und Ausfallsicherheit im System sowie eine leichtere Erweiterbarkeit an den Außengrenzen der Stadt erreichen.
- Welche Rolle spielt hierbei die Künstliche Intelligenz und welche Methoden haben Sie benutzt?
- Thomas Liebig: Wir setzen an dieser Stelle verschiedene Verfahren der Künstlichen Intelligenz ein. Zum einen ist da der Algorithmus, der uns die Prognosen liefert: Das ist eine Regression, wir wollen einen Wert in der Zukunft prognostizieren. Wir Ressourcenbeschränwollen wissen, wie hoch er ist – gegeben an den aktuellen und vergangenen Verkehrsbeobachtungen und unserer Kenntnis über die physikalischen Eigenschaften von Verkehr. Ein weiteres Verfahren ist das der Berechnung des kürzesten Weges, was in diesem Fall mit dynamischen Prognosen und Einbeziehung des öffentlichen Personennahverkehrs noch immer schnell gelingen muss.10
- Und was war das Ergebnis des Vergleichs?
- Thomas Liebig: Wir haben den Kommunikationsaufwand gemessen, weil das Senden bei verteilten Geräten sehr viel Energie verbraucht und Kosten verursacht. Dabei stellte sich heraus, dass wir mit dem dezentralen Modell sechsmal weniger Daten verschickt haben als bei dem zentralen Modell.
Nachhaltigkeit von KI-Modellen
- Können der Pflegeaufwand beziehungsweise die Nachtrainierbarkeit als Nachhaltigkeitskriterien für KI-Modelle verwendet werden?
- Thomas Liebig: Die Nachtrainierbarkeit stellt auf die Frage ab, was passiert, wenn neue Daten kommen: Müssen wir das gesamte Modell neu trainieren oder können wir diese neuen Daten einbeziehen und das Lernen fortsetzen? Das ist eine sehr spannende Frage. Eine weitere Forschungsfrage bezieht sich auf die Lernphase und Anwendungsphase. Hier stellt sich die Frage, welche Modelle sich über längere Zeit effizient und handhabbar anwenden lassen. Unsere Forschung beispielsweise befasste sich ja mit der ressourcensparenden Anwendbarkeit von KI. Wir stellten fest, dass wir bei den probabilistischen Schaltkreisen, die sich für Verkehrsprognosen gut eignen, die aktuellen Messwerte eingeben und sehr schnell die Prognose für die Zukunft erhalten können.11 Diese Modellklasse hat damit einen sehr spannenden, neuen Weg jenseits tiefer neuronaler Netze aufgezeigt.
- 5) Intelligent Synthesis and Real-time Response using Massive Streaming of Heterogeneous Data (INSIGHT), hhttps://cordis.europa.eu/project/id/318225
- 6) Liebig,T., Piatkowski, N., Bockermann, C. & Morik, K. (2017): Dynamic Route Planning with Real-Time Traffic Predictions, Information Systems, Band 64, S. 258 – 265.
- 7) Liebig, T., Sotzny, M. (2017): On Avoiding Traffic Jams with Dynamic Self-Organizing Trip Planning, in: 13th International Conference on Spatial Information Theory (COSIT 2017), Clementini, E., Donnelly, M., Yuan, M., Kray, C., Fogliaroni, P. & Ballatore. A. (Hrsg.), Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2017, Band 86, S.17:1 – 17:12.
- 8) Liebig, T., Stolpe, M. & Morik, K. (2015): Distributed Traffic Flow Prediction with Label Proportions: From in-Network towards High Performance Computation with MPI. In: Andrienko,G., Gunopulos, D., Katakis, I., Liebig, T., Mannor, S., Morik, K. & Schnitzler, F. (Hrsg.), Proceedings of the 2nd International Workshop on Mining Urban Data (MUD2), CEUR-WS [S. 36 – 43], http://ceur-ws.org/Vol-1392/paper-05.pdf
- 9) Stolpe, M., Liebig, T. & Morik, K. (2015): Communication-efficient learning of traffic flow in a network of wireless presence sensors, in: Proceedings of the Workshop on Parallel and Distributed Computing for Knowledge Discovery in Data Bases. http://www.thomas-liebig.eu/wordpress/wp-content/papercite-data/pdf/stolpe15.pdf
- 10) Liebig T., Peter S., Grzenda M. & Junosza-Szaniawski K. (2017): Dynamic Transfer Patterns for Fast Multi-modal Route Planning, in: Bregt, A., Sarjakoski, T., van Lammeren, R. & Rip, F. (Hrsg.), Societal Geo-innovation. AGILE 2017. Lecture Notes in Geoinformation and Cartography [S. 223 – 236]. Cham: Springer Nature Switzerland AG.
- 11) Shao, X. et al. (2020): Conditional Sum-Product Networks: Composing Neural Networks into Probabilistic Tractable Models, in: Proceedings of the 10th International Conference on Probabilistic Graphical Models. https://pgm2020.cs.aau.dk/wp-content/uploads/2020/09/shao20.pdf
- zurück
- 3
- vorwärts
- Was passiert – um beim Beispiel zu bleiben –, wenn die Verkehrswende tatsächlich funktioniert und immer mehr Leute zu Fuß gehen, das Rad nehmen oder auf den ÖPNV umsteigen? Gerät Ihr Modell an die Grenzen, weil dann neue, andere Datenquellen berücksichtigt werden müssen?
- Thomas Liebig: Wenn es so eine Verschiebung innerhalb des Individualverkehrs gibt, unterscheiden sich die Beobachtungen. Diese werden im Modell für die Prognose genutzt und folglich ändern sich auch die Prognosen. Das Modell für Automobilität bleibt somit weiter anwendbar, doch ein Modell für multimodalen Verkehr mit Fahrradmobilität oder ÖPNV hätte sicherlich dann einen höheren Nutzen.
So ein holistisches Modell lässt sich natürlich aus verschiedenen Einzelmodellen für die Verkehrsmodi zusammensetzen. An dieser Stelle haben wir ein Modell für die Stadt Warschau angesetzt und einen multimodalen Routenplaner gebaut. Dort betrachten wir nicht nur Individualverkehr, sondern auch Busse und Bahnen. Wir haben Prognosen für die Verspätungen gemacht, die Verfügbarkeit der Fahrräder und so weiter und in Abhängigkeit von der Verfügbarkeit multimodale Routen bestimmt. Mit den sich ändernden Prognosen ändern sich auch die Routen. Es kann im Einzelfall sinnvoll sein, noch paar Minuten zu Hause zu warten und erst dann loszufahren, statt sofort loszugehen und den ersten Bus zu nehmen.
- Haben Sie die Ampelphasen dabei berücksichtigt?
- Thomas Liebig: Nein, wir haben hier mit größeren Zeitintervallen gearbeitet. Im Moment schauen wir uns im Sonderforschungsbereich 876 an der TU Dortmund den städtischen Verkehr sehr detailliert im Hinblick auf Mischverkehr mit automatisierten Fahrzeugen an.12 Hier interessiert dann, wie Fahrzeuge mit ihrer Umgebung kommunizieren können, um Verkehrsnetze effizienter zu nutzen und Staus zu vermeiden. Für diese höhere zeitliche Granularität sind die physikalischen Beobachtungen von Verkehr nicht direkt übertragbar und wir müssen neue Modelle zur Prognose entwickeln. Dabei achten wir darauf, dass die Modelle unter Ressourcenbeschränkungen effizient nutzbar sind – mit Blick auf die Genauigkeit, Laufzeit und Anwendbarkeit. Die Verwendung von probabilistischen Schaltkreisen ist ein vielversprechender Ansatz in diese Richtung, der bislang gute Ergebnisse gezeigt hat.
Anonymisierte Cluster-Erfassung
- In welchen anderen Anwendungsbereichen könnte man ein dezentrales IoT-basiertes KI-Modell einsetzen?
- Thomas Liebig: Eine Dezentralisierung der Analysen und Prognosen auf Basis ressourcenbeschränkter Geräte hat den Vorteil, dass man nicht nur anonymisiert, sondern auch energiesparend arbeiten kann. Durch die lokale Aggregation der Echtzeitwerte kann ein einzelner Verkehrsteilnehmer nicht mehr identifiziert werden, womit sich auch einzelne Bewegungsprofile verhindern lassen. Generell ist es relevant für Smart Sensing beziehungsweise das IoT-gestützte Monitoring großer Räume, etwa für die dezentrale Beobachtung der Umgebungstemperatur oder des CO2-Gehalts in Städten.13
- Kann man mit dieser Methode auch zuverlässige und datenschutzkonforme Aussagen zu Clustern machen?
- Thomas Liebig: Ja, beispielsweise möchte man für Evakuierungsanwendungen und Verkehrsplanung wissen, wo sich wann wie viele Menschen etwa im Rahmen eines Fußballspiels aufhielten – und vielleicht auch, woher die Leute kamen und ob sie sich an den Zugängen zu dem Fußballstadion auf engstem Raum gedrängt haben. Dazu gibt es kryptografische Methoden, die auch im E-Voting-System Anwendung finden: Die Daten werden dabei lokal verschlüsselt und zu einem Server übertragen. Der Server aggregiert und rechnet dann mit KIMethoden mit den verschlüsselten Daten. Erst das Ergebnis kann im Nachgang entschlüsselt werden.14 Diese Verfahren sind im Moment noch sehr ressourcenaufwendig: Sie benötigen viel Rechenzeit und -leistung, sowohl auf den Servern wie auch lokal auf den Geräten, wo sie die Daten verschlüsseln. Deshalb werden sie momentan noch nicht verbreitet angewandt.15
- Wäre bei einem solchen Verfahren, das verschlüsselte Daten auswertet, noch eine Deanonymisierung möglich?
- Thomas Liebig: Eine Deanonymisierung ist nicht möglich, weil sich nur das Ergebnis, aber nicht die einzelnen Daten entschlüsseln lassen. Das basiert auf der Annahme, dass das zugrunde liegende „Ring Learning with Errors“-Problem16 schwierig ist.
- Wie lässt sich das Problem lösen, dass solche datenschutzkonformen Verfahren keine Verbreitung in der Praxis finden, weil sie zu viel Energie verbrauchen?
- Thomas Liebig: Die Parametrisierung dieser Verfahren ist in der Praxis eben schwer. Man muss einen Kompromiss zwischen der Anwendbarkeit der Verfahren dieser homomorphen Verschlüsselung und deren Sicherheit erreichen. Mit der Veröffentlichung von Bibliotheken für homomorphe Verschlüsselung von Microsoft17 und IBM18 sind diese Algorithmen auch außerhalb der Forschung effizient anwendbar. Dennoch benötigt es Best Practices und Studien zur Parametrisierung der komplexen Verfahren für konkrete Anwendungen. Bisherige akademische Arbeiten auf dem Gebiet sind dazu wenig geeignet, da die Forschung zu homomorpher verschlüsselter Datenanalyse noch recht jung ist. Aktuell befassen sie sich häufig noch mit der Erweiterung des Möglichen und noch nicht mit der Überführung in die Praxis.
- 12) Sonderforschungsbereich 876 – Verfügbarkeit von Information durch Analyse unter Ressourcenbeschränkung: B4 Analyse und Kommunikation für die dynamische Verkehrsprognose, https://sfb876.tu-dortmund.de/SPP/sfb876-b4.html
- 13) Sanders, C., Liebig, T. (2020): Knowledge Discovery on Blockchains: Challenges and Opportunities, in: Proceedings of the ECML Workshop on Parallel, Distributed, and Federated Learning.
- 14) Liebig, T. (2015): Privacy Preserving Centralized Counting of Moving Objects, in: Bacao, F., Santos, M., M. Y. & Painho, M. (Hrsg.), AGILE 2015 – Geographic Information Science as an Enabler of Smarter Cities and Communities [S. 91 – 103]. Cham: Springer International Publishing Switzerland.
- 15) Einen Überblick über die Parametrisierung der Fan-Vercauteren-Verschlüsselung für einen häufig genutzten Clusteralgorithmus (k-means) hat Sebastian Schröder im Rahmen seiner Bachelorarbeit an der TU Dortmund erstellt: Schröder, S. (2018): K-means auf verschlüsselten Daten: FV im Praxiseinsatz, TU Dortmund, Bachelorarbeit.
- 16) Lyubashevsky, V., Peikert, C. & Regev, O. (2010): On ideal lattices and learning with errors over rings, in: Annual International Conference on the Theory and Applications of Cryptographic Techniques, [S. 1 – 23]. Berlin/Heidelberg: Springer.
- 17) Microsoft SEAL, Microsoft Research, https://www.microsoft.com/en-us/research/project/microsoft-seal/
- 18) Fully Homomorphic Encryption (FHE), IBM Research, https://research.ibm.com/topics/fully-homomorphic-encryption
- zurück
- 4
- vorwärts
Wege in die Ressourcensparsamkeit
- KI-Modelle werden bekanntermaßen ja besser, wenn sie mit möglichst vielen unterschiedlichen Daten gefüttert werden. Hat Datensparsamkeit überhaupt eine Chance und wie hängt diese mit den Ansätzen zusammen, die Sie gerade geschildert haben?
- Thomas Liebig: Die Menge der Daten beeinflusst die Laufzeit der Algorithmen. Man misst also auch bei KI-Algorithmen deren Komplexität. Angenommen, es werden doppelt so viele Daten verarbeitet, steigt dann die Laufzeit des Algorithmus doppelt an oder quadratisch? Also in welcher Laufzeitklasse bewegt sich das gewählte Verfahren? Deswegen sind Verfahren interessant, die zum Trainieren besonders wenig Daten brauchen. Die spannende Frage ist, ob man die Ergebnisse, die man mit Big Data und neuronalen Netzen erzielen kann, auch mit weniger Daten erreichen kann. Das ist Forschungsgegenstand zum Beispiel bei handhabbaren Modellen wie probabilistischen Schaltkreisen.19
Es gibt bereits viele Entwicklungen, bei denen sich mit weniger Daten bessere Ergebnisse erzielen lassen. Das geht natürlich, wenn Strukturen wie beispielsweise Symmetrien in den Daten genutzt oder Domänenwissen einbezogen werden können. Aber es gibt neben dem Lernen auch viele Aspekte, die die Menge der Daten beeinflussen. Zum Beispiel brauche ich Energie, die Daten zu speichern. Die Daten müssen kommuniziert werden, damit sie im System ankommen. Die Berechnungen dauern länger, je mehr Daten es gibt. Diese Aspekte beeinflussen natürlich die Effizienz des Verfahrens und auch den CO2-Fußabdruck.
- Was motiviert also zur Ressourcensparsamkeit, ist es eine sanktionierende Datenregulierung wie die DSGVO oder wären es auch steigende Kosten aufgrund einer CO2-Bepreisung oder das Einfordern bestimmter Systemeigenschaften in Ausschreibungen? Oder alles zusammen?
- Thomas Liebig: Alle zusammen sind die treibende Kraft. Es gibt Anwendungen wie die Analyse von Gendaten oder Mobilitätsdaten, die den Schutz der Privatsphäre sehr in den Fokus stellen. Hier ist der Trade-off-Energieverbrauch versus Privacy20 natürlich deutlich zugunsten der Privacy21. Viele Anwendungen schauen dann aber auf die Kosten des Gesamtsystems und damit auch auf die Energiekosten, um die Wirtschaftlichkeit des Gesamtsystems zu bewerten. Die Hinterfragung und Überprüfung von zahlreichen etablierten IT-Systemen und Prozessen nach deren Ressourcenbedarf kann die nötige Motivation freisetzen, ressourcensparende Methoden der KI und Automatisierung einzusetzen, und den Transfer von Künstlicher Intelligenz in die Gesellschaft vorantreiben.
- 19) Choi, Y., Vergari, A., & Broeck, G. V. (2020). Lecture Notes Probabilistic Circuits: Representation and Inference.
- 20) Potlapally, N. R., Ravi, S., Raghunathan, A., & Jha, N. K. (2005): A study of the energy consumption characteristics of cryptographic algorithms and security protocols. IEEE Transactions on mobile computing, 5(2), S. 128 – 143.
- 21) Mittos, A., Malin, B., & De Cristofaro, E. (2019): Systematizing genome privacy research: A privacy-enhancing technologies perspective, Proceedings on Privacy Enhancing Technologies, S. 87 – 107.
- zurück
- 5
Hintergrund
Auf dem Weg zur grünen KI
Welche Emissionen die Nutzung von KI-Modelle, KI-Anwendungen, aber auch Software-Programme im Allgemeinen verursachen, ist noch immer weitgehend unbekannt. Der französische Thinktank „Shift Project“, der systematisch Unternehmensberichte und Studien auf genauere Angaben zur Klimawirksamkeit von Digitalprodukten untersucht, weist darauf hin, dass die veröffentlichten Daten noch immer zu selten präzise Schlussfolgerungen zulassen, obwohl seit 2019 unter der Maßgabe der Transparenz immer mehr Daten veröffentlicht wurden. Daher gebe es auch keine Aussagen zu einzelnen Unternehmen.1
Scope 3 bleibt ein Graubereich
Das Kernproblem ist der sogenannte Scope 3: Er umfasst Emissionen, die in der vor- oder nachgelagerten Lieferkette verursacht werden, aber nicht unter der unmittelbaren Kontrolle von Herstellern und Dienstleistern stehen. In den Nachhaltigkeitsberichten von Unternehmen werden inzwischen Angaben zu Emissionen gemacht, die nach dem GHG-Protokoll Scope 1 etwa bei unternehmenseigenen Flotten oder Kraftwerken betreffen sowie nach Scope 2 die vom Unternehmen bezogenen Energiedienstleistungen. Angaben zu Scope 3 beziehen sich meist auf die Mobilität von Mitarbeitern.
Bisher ist kein großes Digitalunternehmen bekannt, das seinen gesamten Scope 3 beziffern könnte. So auch Apple, Google und Microsoft, die gleichwohl für ihre relativ ausführlichen Angaben die A-Note des Carbon Disclosure Project (CDP) erhalten haben. Immerhin stellen sie für die nächsten Jahre mehr Detailangaben zu Scope 3 in Aussicht. Der Grund: Immer mehr Investoren, die in nachhaltige grüne Projekte investieren wollen, drängen auf Klarheit. Für Druck sorgt auch die EU-Kommission, die von den Unternehmen nach dem Grundsatz der sogenannten „Doppelten Wesentlichkeit“ auch Angaben darüber verlangt, wie ein Unternehmen auf das Klima wirkt.2
Energieintensive KI-Modelle
Forscher tasten sich derzeit an das Thema Nachhaltigkeit von KI-Projekten heran. Für Aufsehen sorgte die Forschergruppe um Emma Strubell 2019 mit ihrer Energieanalyse von KI-Sprachmodellen. Demnach soll ein Trainingslauf für das NAS-Sprachmodell rund 284 Tonnen CO2 erzeugen, was dem Ausstoß von fünf durchschnittlichen US-Pkws während ihrer gesamten Lebenszeit entspreche. Ein Trainingslauf von Googles Sprachmodell BERT, auf dem die Suchmaschine basiert, entspreche knapp dem Hin- und Rückflug zwischen New York City und San Francisco, wobei diese Trainingsläufe laufend wiederholt werden.
In einem aktuellen Paper stellen unabhängige US-Forscher um Roy Schwartz fest, dass sich der Rechenaufwand für modernste KI-Forschung in den letzten Jahren um das 300.000-fache erhöht hat. Dieser Trend der „Roten Künstliche Intelligenz“ rühre daher, dass KI-Entwickler auf Effizienz und Genauigkeit gleichermaßen großen Wert legen, was jedoch mit seinem enormen Energieverbrauch zu einem sehr großen CO2-Fußabdruck führe. Die Forscher haben die Unternehmensrechenzentren von Microsoft und Google im Blick, die es sich leisten können, riesige Ressourcen für Brute-Force-Versuche zur Verbesserung der Genauigkeit aufzubringen.
Gerade für Wissenschaftler und Studierende an Universitäten ist dieser Ressourcenaufwand bei „Deep Learning“-Projekten nicht zu stemmen. Insofern können sie auch die erzielten Ergebnisse nicht reproduzieren und überprüfen. Als Alternative schlagen die Forscher die Entwicklung sogenannter „Grüner KI“ vor, die Effizienz als primäres Bewertungskriterium setzt. Generell bleibt aber auch hier eine genaue Bestimmung des CO2-Fußabdrucks schwierig, weshalb die Wissenschaftler dafür plädieren, etwa mit verschiedenen KI-Modellgrößen Budget-Performance-Analysen vorzunehmen.3
Mangels Daten lässt sich auch die Frage, wie viel Gramm CO2 bestimmte Eingaben in Spracherkennungssysteme verursachen, nicht beantworten. Das Umweltsiegel für Digitaltechnik, der „Blaue Engel“, deckt zwar seit 2020 nicht nur Hardware, sondern auch Software ab, doch Cloud-Dienste sind derzeit noch ausgenommen. Bei Cloud-Diensten müsste man auch berechnen können, welche Energiekosten die Anwendungen in bestimmten Rechenzentren verursachen.
Rechenzentren im Visier
Die EU-Kommission hat für europäische Rechenzentren das Ziel Net-Zero für das Jahr 2030 festgelegt. Laut einer Kurzstudie des Borderstep Institute zum Energieverbrauch europäischer Rechenzentren hat sich in den letzten zehn Jahren der Energiebedarf der Digitalisierung in Europa von 57 Terawattstunden pro Jahr im Jahr 2010 auf 88 TWh/a im Jahr 2020 erhöht. Weitere Steigerungen seien zu erwarten: Im vergangenen Jahrzehnt hat sich zwar der Energiebedarf in Bezug auf Rechen- und Speicherleistung um den Faktor sechs bis zwölf verringert, doch die Zahl der Workloads in den Rechenzentren hat sich im gleichen Zeitraum um den Faktor zehn erhöht.
Die Location der Rechenzentren spielt bei der Bewertung ihres CO2-Fußabdrucks eine Rolle, da hier der nationale Strommix maßgeblich ist. So ist etwa in skandinavischen Rechenzentren der CO2-Fußabdruck aufgrund eines hohen Anteils erneuerbarer Energien sehr viel geringer als in Polen und Estland. Deutschland liegt mit 420 g CO2/kWh in der Mitte. Effizienzschübe sind durch cloudbasierte Lösungen zu erwarten. Rechenzentren-Technologien wie Kühlung und Klimatisierung versprechen weitere Einsparpotenziale, etwa mit Kältemitteln ohne Treibhauspotenzial. 30 Prozent des Einsparpotenzials seien mit optimierter Software und Algorithmen erreichbar.
Beispielsweise nutzt das Eurotheum in Frankfurt/Main mit einem wasserbasierten Direktkühlsystem rund 70 Prozent seiner eigenen Abwärme, um Büro- und Konferenzräume sowie die Hotels und Gastronomie vor Ort zu beheizen. Der GreenIT Cube für den Supercomputer am GSI-Helmholtzzentrum für Schwerionenforschung in Darmstadt spart jährlich etwa 15.000 Tonnen CO2-Emissionen ein. Eine Kaltwasserkühlung in den Türen der Rechnerschränke ersetzt die Raumluftkühlung und erreicht eine sehr hohe Effizienz von weniger als 1,07 PUE. Die Kennzahl PUE drückt die Power Usage Effectiveness aus, indem sie die insgesamt in einem Rechenzentrum verbrauchte Energie ins Verhältnis setzt zu der Energieaufnahme der IT-Infrastruktur. In diesem Fall werden weniger als sieben Prozent der elektrischen Energie für die Kühlung benötigt.
Diese Best-Practice-Beispiele sind Ausnahmen. In der Praxis lässt sich an anderer Stelle mehr in Sachen Energieeffizienz erreichen, etwa mit einer besseren Auslastung der Server in Rechenzentren. Wie schnell Rechenzentren klimaneutral werden, hängt auch davon ab, wie schnell sich Effizienztechniken im Markt durchsetzen bzw. in welchen Abständen der Gerätepark modernisiert wird.
- 1) The Shift Project (2020): A-t-il vraiment surestimé l’empreinte carbone de la video en ligne? Notre analyse des articles de l’aie et et de carbonbrief, F, 15. Juni 2020, https://theshiftproject.org/article/shift-project-vraiment-surestime-empreinte-carbone-video-analyse
- 2) Siehe Hintergrund: Standards in der CSR-Berichterstattung
- 3) Siehe Interview mit Thomas Liebig: KI-Systeme: Vom Algorithmus zum CO2-Fußabdruck.
Literatur
Shao, X., Molina, A., Vergari, A., Stelzner, K., Perharz, R., Liebig, T. & Kersting, K. (2020): Conditional Sum-Product Networks: Composing Neural Networks into Probabilistic Tractable Models; Proceedings of the 10th International Conference on Probabilistic Graphical Models.
Sanders, C. & Liebig, T. (2020): Knowledge Discovery on Blockchains: Challenges and Opportunities. Proceedings of the ECML Workshop on Parallel, Distributed, and Federated Learning.
Liebig, T., Stolpe, M. & Morik, K. (2015): Distributed Traffic Flow Prediction with Label Proportions: From in-Network towards High Performance Computation with MPI, in: Andrienko, G., Gunopulos, D., Katakis, I., Liebig, T., Mannor, S., Morik, K. & Schnitzler, F. (Hrsg.), Proceedings of the 2nd International Workshop on Mining Urban Data (MUD2), CEUR-WS [S. 36 – 43], http://ceur-ws.org/Vol-1392/paper-05.pdf
Weiterlesen zum Thema:
Hintemann, R. & Clausen, J. (2020): Bedeutung digitaler Infrastrukturen in Deutschland, Chancen und Herausforderungen für Rechenzentren im internationalen Wettbewerb. Berlin: Borderstep Institut.
Schwartz, R., Dodge, J., Smith, N. A. & Etzioni, O. (2020): Green AI, in: Communications of the ACM, 63(12), S. 54 – 63; Strubell, E., Ganesh, A., McCallum, A. (2019): Energy and Policy Considerations for Deep Learning in NLP; https://arxiv.org/pdf/1906.02243.pdf
Strubell, E., Ganesh, A. & McCallum, A. (2019): Energy and Policy Considerations for Deep Learning. Annual Meeting of the Association for Computational Linguistics. https://arxiv.org/pdf/1906.02243.pdf
Sculley, D. et al. (2015): Hidden technical debt in machine learning systems. Advances in neural information processing systems, S. 2503 – 2511.
Das Interview mit Thomas Liebig führte die Journalistin Christiane Schulzki-Haddouti im Rahmen eines vom Bundesministerium für Bildung und Forschung beauftragten Publikationsprojektes zum Thema „KI und Nachhaltigkeit“. Die vollständige Publikation steht als PDF zum Download zur Verfügung.